
01.09.2022 · Peter Peltzer
Warum investieren so viele Unternehmen in Ihre Datenarchitektur?
Datengetriebene Unternehmen generieren kontinuierlich Mehrwert durch ihre strategische Nutzung. Bevor man beginnen kann, Daten zu analysieren, müssen diese konstant verfügbar und abrufbar sein. Will man Daten in Echtzeit auswerten, stellt dies eine noch größere Herausforderung dar. Eines ist zumindest klar: Die Datenarchitektur muss so aufgebaut sein, dass Transfers reibungslos und in Echtzeit stattfinden. Eine Möglichkeit, diese Herausforderung zu meistern, bietet Apache Kafka.
Kafka ist eine Software, welche event-driven Data-Streaming ermöglicht. Damit wird nichts anderes als Live-Kommunikation zwischen Systemen aktiviert. Kommunikation zwischen Systemen findet häufig in Form von Batch-Processing statt. Bei zunehmender Datenkomplexität wird die Anzahl an Jobs, die Daten in Batches transferiert, nicht mehr überschaubar – Kafka beseitigt dieses Problem, indem es auf reine Simplizität setzt.
In Kafka werden alle Datenquellen „Producers" genannt und generieren Events. Diese werden an Kafka gesendet und Consumer können sie dann konsumieren. Um eine adäquate Übersicht zu gewährleisten, benutzt Kafka sogenannte Topics – Container für zusammengehörige Events. Alle Bestellungen fließen z. B. in das Topic „Bestellungen", alle Retouren in das Topic „Retouren". Diese werden in Kafka in sogenannte Partitionen aufgeteilt, wobei ein Event als Message bezeichnet und einer Partition eines Topics zugewiesen wird.
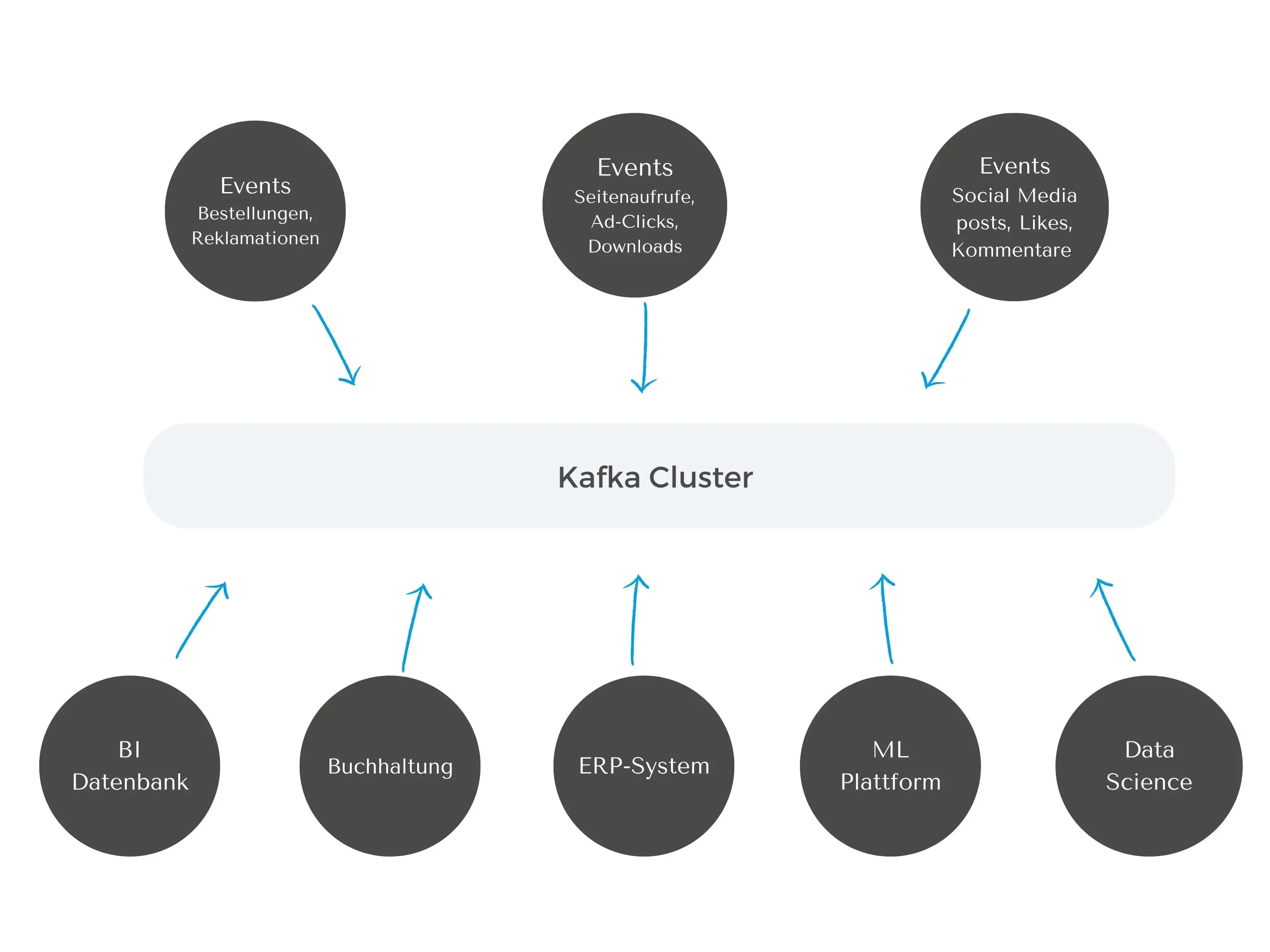
Was ist Apache Kafka?
[01.01.22] Kunde Nr. 101 bestellt Artikel Nr. 001.
[10.03.22] Kunde Nr. 101 bestellt Artikel Nr. 002.
[15.03.22] Kunde Nr. 101 schickt Artikel Nr. 002 zurück.Kafka ist ein Message Broker und ersetzt keine Datenbank. Der Mehrwert liegt in der Skalierbarkeit und in der Reduzierung der Code Base und Komplexität. Kafka hilft das Bottleneck zu vermeiden, indem es von allen Producern die Daten als Events aufnimmt und beliebig viele Consumer füttert. So werden aus einer großen Monolith App mehrere Microservices, die leichter zu handhaben sind.

Data Engineers bauen mit Kafka skalierbare und schnelle Daten-Pipelines. Die Producer API sendet Messages aus verschiedenen Quellen an Topics in einem Kafka Cluster. Mit der Consumer API werden die Messages aus den Topics gezogen und gelesen. Die Stream API zieht Messages aus einem Topic, transformiert sie und lädt diese in einem anderen Topic. Die Connect API bezeichnet die Schnittstelle zwischen Kafka Cluster und Zielsystem der Consumer – z. B. eine SQL-Datenbank, eine CSV-Datei oder eine Cloud-Plattform.
Die hohe Simplizität von Kafka ist zwar einer der Hauptgründe für seinen Einsatz, hat aber ihren Preis. Kafka ist keine Universallösung: Wer größere Datenmengen speichern möchte, sollte nicht auf Kafka setzen, da sich redundante Datensätze anhäufen. Die Schwächen überschatten jedoch keinesfalls die vielen Vorteile – weshalb Kafka auch von LinkedIn, Cisco und Goldman Sachs genutzt wird.

Daten in Echtzeit zur Verfügung zu stellen, wird für viele Unternehmen zunehmend wichtiger. Kafka bietet eine einfache und schnell umsetzbare Lösung und kann die Anwendungsentwicklung zum Event-Stream-Processing beschleunigen. „Easy to operate, easy to set up and very easy to deploy" sind die Grundmerkmale von Kafka. Wem Features fehlen und wer auf die leichte Handhabbarkeit verzichten kann, ist mit umfassenderen Alternativen wie z. B. Apache Pulsar besser bedient. Der Einstieg in eine event-basierte Streaming-Architektur kann sich durchaus lohnen, um die Qualität und Performance der Datenverteilung voranzutreiben.
Vereinbaren Sie ein kostenfreies Erstgespräch. Kein Overhead, kein Verkaufsgespräch – nur echter Mehrwert.